Just back from an amazing week at the OpenStack Summit in Hong-Kong, I
would like to share a number of discussions we had (mainly on the
release management
track)
and mention a few things I learned there.
First of all, Hong-Kong is a unique city. Skyscrapers built on
vertiginous slopes, crazy population density, awesome restaurants, shops
everywhere... Everything is clean and convenient (think: Octopus cards),
even as it grows extremely fast. Everyone should go there at least one
time in their lives !
On the Icehouse Design Summit side,the collaboration magic happened
again. I should be used to it by now, but it is still amazing to build
this level playing field for open design, fill it with smart people and
see them make so much progress over 4 days. We can still improve,
though: for example I'll make sure we get whiteboards in every room for
the next time :). As was mentioned in the feedback session, we are
considering staggering the design summit and the conference (to let
technical people participate to the latter), set time aside to discuss
cross-project issues, and set up per-project space so that collaboration
can continue even if there is no scheduled "session" going on.
I have been mostly involved in release management
sessions.
We discussed the Icehouse release
schedule,
with a proposed release date of April 17, and the possibility to
have a pre-designated "off" week between release and the J design
summit. We discussed changes in the format of the weekly
project/release status
meeting, where
we should move per-project status updates off-meeting to be able to
focus on cross-project issues instead. During this cycle we should also
work on streamlining library release announcements. For stable branch
maintenance, we decided to officially drop support for version n-2 by
feature freeze (rather than at release time), which reflects more
accurately what ended up being done during the past cycles. The security
support is now aligned to stable branch support, which should make sure
the vulnerability management team (VMT) doesn't end up having to
maintain old stable branches that are already abandoned by the stable
branch maintainers. Finally, the VMT should review the projects from all
official programs to come up with a clear list of what projects are
actually security-supported and which aren't.
Apart from the release management program, I'm involved in two pet
projects: Rootwrap and
StoryBoard.
Rootwrap should be split from the oslo-incubator into its own
package early in the Icehouse cycle, and its usage in Nova, Cinder and
Neutron should be reviewed to result in incremental strengthening.
StoryBoard (our next-generation task tracker) generated a lot of
interest at the summit, I expect a lot of progress will be made in the
near future. Its architecture might be overhauled from the current POC,
so stay tuned.
Finally, it was great meeting everyone again. Our PTLs and Technical
Committee members are a bunch of awesome folks, this open source project
is in great hands. More generally, it seems that we not only designed a
new way of building software, we also created a network of individuals
and companies interested in that kind of open collaboration. That
network explains why it is so easy for people to jump from one company
to another, while continuing to do the exact same work for the OpenStack
project itself. And for developers, I think it's a great place to be in:
if you haven't already, you should definitely consider joining us.
When we
changed
the Technical Committee membership model to an all-directly-elected
model a few months ago, we proposed we would enable detailed ballot
reporting in order to be able to test alternative algorithms and run
various analysis over the data set. As an official for this election,
here is my analysis of the
results,
hoping it will help in the current discussion on a potential evolution
of the Foundation individual members voting system.
Condorcet method
In the OpenStack technical elections, we always used the Condorcet
method (with the Schulze completion method), as implemented by
Cornell's CIVS public
voting system. In a Condorcet vote, you rank your choices in order of
preference (it's OK to rank multiple choices at the same level). To
calculate the results, you simulate 1:1 contests between all candidates
in the set. If someone wins all such contests, he is the Condorcet
winner for the set. The completion method is used to determine the
winner when there is no clear Condorcet winner. Most completion methods
can result in ties, which then need to be broken in a fair way.
Condorcet spread
One thing we can analyze is the spread of the rankings for any given
candidate:
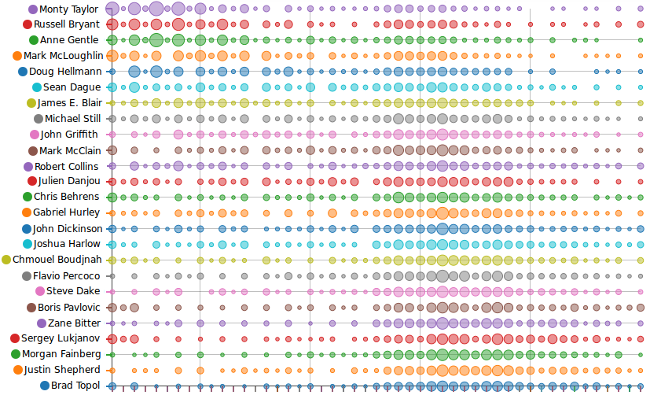
On that graph the bubbles on the left represent the number of high
rankings for a given candidate (bubbles on the right represent low
rankings). When multiple candidates are given the same rank, we average
their ranking (that explains all those large bubbles in the middle of
the spectrum). A loved-or-hated candidate would have large bubbles at
each end of the spectrum, while a consensus candidate would not.
Looking at the graph we can see how Condorcet favors consensus
candidates (Doug Hellmann, James E. Blair, John Griffith) over
less-consensual ones (Chris Behrens, Sergey Lukjanov, Boris Pavlovic).
Proportional Condorcet ?
Condorcet indeed favors consensus candidates (and "natural" 1:1 election
winners). It is not designed to represent factions in a proportional
way, like STV is. There is an experimental proportional representation
option in CIVS software though, and after some ballot conversion we can
run the same ballots and see what it would give.
I set up a test election and the results are
here.
The winning 11 would have included Sergey Lukjanov instead of John
Griffith, giving representation to a less-consensual candidate. That
happens even if a clear majority of voters prefers John to Sergey (John
defeats Sergey in the 1:1 Condorcet comparison by 154-76).
It's not better or worse, it's just different... We'll probably have a
discussion at the Technical Committee to see whether we should enable
this experimental variant, or if we prefer to test it over a few more
elections.
Partisan voting ?
Another analysis we can run is to determine if there was any
corporate-driven voting. We can look at the ballots and see how many of
the ballots consistently placed all the candidates from a given company
above any other candidate.
7.8% of ballots placed the 2 Mirantis candidates above any other. 5.2%
placed the 2 IBM candidates above any other. At the other end of the
spectrum, 0.8% of ballots placed all 5 Red Hat candidates above any
other, and 1.1% of the ballots placed all 4 Rackspace candidates above
any other. We can conclude that partisan voting was limited, and that
Condorcet's preference for consensus candidates further limited its
impact.
What about STV ?
STV is another ranked-choice election method, which favors proportional
representation. Like the "proportional representation" CIVS option
described above, it may result in natural Condorcet winners to lose
against more factional candidates.
I would have loved to run the same ballots through STV and compare the
results. Unfortunately STV requires strict ranking of candidates in an
order of preference. I tried converting the ballots and randomly
breaking similar rankings, but the end results vary extremely depending
on that randomness, so we can't really analyze the results in any useful
way.
Run your own analysis !
That's it for me, but you can run your own analysis by playing with the
CSV ballot file yourself ! Download it
here,
and share the results of your analysis if you find anything interesting
!
.
Yesterday, as the final conclusion of the 6-month "Havana" development
cycle, we released the latest version of
OpenStack,
the 2013.2 version. It's now composed of 9 integrated components, which
saw the completion of more than 400 feature blueprints and the fixing of
more than 3000 reported bugs.
As always, it's been an interesting week for me. Not as busy as you'd
think, but lots of hours, day or night, spent frantically checking
dashboards, collecting input from our fearful technical leads, waiting
for a disaster to happen and pushing the right buttons at the right
moment, finally aligning the stars and releasing everything on time.
Yes, I use checklists to make sure I don't overlook anything:
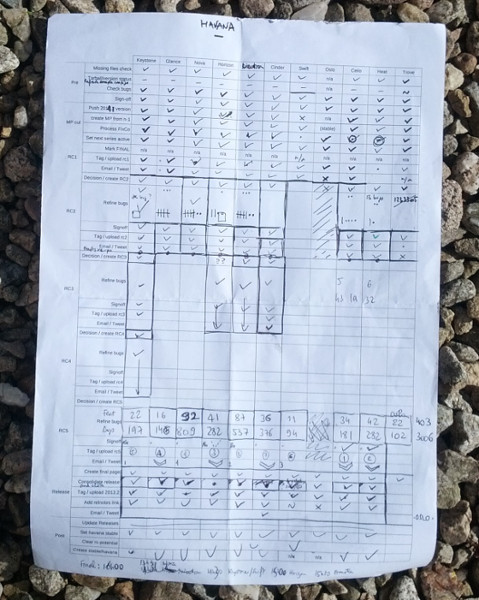
Even if I have plenty of free time between those key hours, I can't
concentrate on getting anything else done, or get something else started
(like a blog post). This is why, one day after release, I can finally
spend some time looking back on the last stage of the Havana development
cycle and see how well we performed. Here is the graph showing the
number of release-critical bugs logged against various components (those
observing the common feature freeze) as we make progress towards the
final release date:
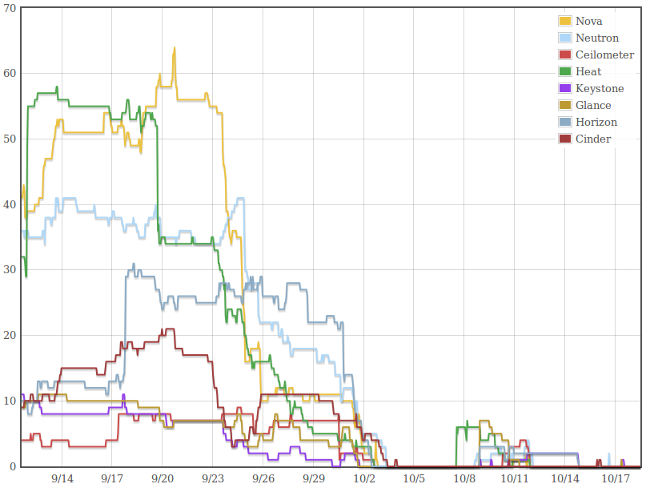
Personally I think we were a bit late, with RC1s globally landing around
October 3 and RC2s still being published around October 15. I prefer
when we can switch to "respin only for major regressions and upgrade
issues" mode at least a week before final release, not two days before
final release. Looking at the graph, we can see where we failed: it took
us 11 days to get a grip on the RC bug count (either by fixing the right
issues, or by stopping adding new ones, or by refining the list and
dropping non-critical stuff). Part of this delay is due to stress
recovery after a rather eventful feature freeze. Part of it is lack of
prioritization and focus on the right bugs. The rest of the graph pretty
much looks like the Grizzly
one. We were
just at least one week too late.
We'll explore ways to improve on that during the Icehouse Design Summit
in Hong-Kong. One solution might be to add a week between feature freeze
and final release. Another solution would be to filter what gets
targeted to the last milestone to reduce the amount of features that
land late in the cycle, to reduce FeatureFreeze trauma. If you want to
be part of the discussion, join us all in
Hong-Kong
in 18 days !
Over the last 3 years, the technical governance of the OpenStack open
source project evolved a lot, and most recently last
Tuesday. As an
elected member of that governance body since April 2011, I witnessed
that evolution from within and helped in drafting the various models
over time. Now seems like a good time to look back in history, and clear
a few misconceptions about the OpenStack project governance along the
way.
The POC
The project was originally created by Rackspace in July 2010 and seeded
with code from NASA (Nova) and Rackspace (Swift). At that point an
initial project
governance
was set up. There was an Advisory Board (which was never really
created), the OpenStack Architecture Board, and technical committees
for each subproject, each lead by a Technical Lead. The OpenStack
Architecture Board had 5 members appointed by Rackspace and 4 elected by
the community, with 1-year to 3-year (!) terms. The technical leads for
the subprojects were appointed by Rackspace.
By the end of the year 2010 the Architecture Board was renamed Project
Oversight Committee (POC), but its structure didn't
change.
While it left room for community input, the POC was rightfully seen as
fully controlled by Rackspace, which was a blocker to deeper involvement
for a lot of the big players in the industry.
It was a danger for the open source project as well, as the number of
contributors external to Rackspace grew. As countless examples prove,
when the leadership of an open source project is not seen as
representative of its contributors, you face the risk of a revolt, a
fork of the code and seeing your contributors leave for a more
meritocratic and representative alternative.
The PPB
In March 2011, a significant change was
introduced
to address this perceived risk. Technical leads for the 3 projects
(Nova, Swift, and Glance at that point) would from now on be directly
elected by their contributors and called Project Technical Leads
(PTLs). The POC was replaced by the Project Policy Board (PPB), which
had 4 seats appointed by Rackspace, 3 seats for the above PTLs, and 5
seats directly-elected by all the contributors of the project. By spring
2012 we grew to 6 projects and therefore the PPB had 15 members.
This was definitely an improvement, but it was not perfect. Most
importantly, the governance model itself was still owned by Rackspace,
which could potentially change it and displace the PPB if it was ever
unhappy with it. This concern was still preventing OpenStack from
reaching the next adoption step. In October 2011, Rackspace therefore
announced
that they would set up an independent Foundation. By the summer of 2012
that move was completed and Rackspace had transfered the control over
the governance of the OpenStack project to the OpenStack
Foundation.
The TC
At that point the governance was split into two bodies. The first one is
the Board of Directors for the Foundation itself, which is responsible
for promoting OpenStack, protecting its trademark, and deciding where to
best spend the Foundation's sponsors money to empower future development
of OpenStack.
The second body was the successor to the PPB, the entity that would
govern the open source project itself. A critical piece in the
transition was the need to preserve and improve the independence of the
technical meritocracy. The bylaws of the Foundation therefore instituted
the Technical Committee, a successor for the PPB that would be
self-governed, and would no longer have appointed members (or any
pay-to-play members). The Technical Committee would be completely
elected
by the active technical contributors: a seat for each elected PTL, plus
5 directly-elected seats.
TC 2.0
The TC started out in September 2012 as an 11-member committee, but with
the addition of 3 new projects (and the creation of a special seat for
Oslo), it grew to 15 members in April 2013, with the perspective to grow
to 18 members in Fall 2013 if all projects applying for incubation
recently get finally accepted. With the introduction of the
"integrated" project
concept (separate
from the "core" project concept), we faced the addition of even more
projects in the future and committee bloat would inevitably ensue. That
created a potential for resistance to the addition of "small" projects
or the splitting of existing projects (which make sense technically but
should not be worth adding yet another TC seat).
Another issue was the ever-increasing representation of "vertical"
functions (project-specific PTLs elected by each project contributors)
vs. general people elected by all contributors. In the original PPB mix,
there were 3 "vertical" seats for 5 general seats, which was a nice mix
to get specific expertise but overall having a cross-project view. With
the growth in the number of projects, in the current TC we had 10
"vertical" seats for 5 general seats. Time was ripe for a reboot.
Various models
were considered and discussed, and while everyone agreed on the need to
change, no model was unanimously seen as perfect. In the end, simplicity
won and we picked a model with 13 directly-elected
members,
which will be put in place at the Fall 2013 elections.
Power to the active contributors
This new model is a direct, representative model, where if you recently
authored a change for an OpenStack project, you get one vote, and a
chance every 6 months to choose new people to represent you. This model
is pretty flexible and should allow for further growth of the project.
Few open source projects use such a direct governance model. In Apache
projects for example (often cited as a model of openness and
meritocracy), the oversight committee equivalent to OpenStack's TC would
be the PMC. In most cases,
PMC membership is self-sustaining: existing PMC members ultimately
decide, through discussions and
votes on the private PMC
list, who the new PMC members should be. In contrast, in OpenStack the
recently-active contributors end up being in direct control of who their
leaders are, and can replace the Technical Committee members if they
feel like they are not relevant or representing them anymore. Oh, and
the TC doesn't use a private list: all our meetings are
public and our
discussions are
archived.
As far as open source projects governance models go, this is as open,
meritocratic, transparent and direct as it gets.
The beginning of a new release cycle is as good as any moment to
question why we actually go through the hassle of producing OpenStack
releases. Twice per
year, on a precise date
we announce 6 months in advance, we bless and publish source code
tarballs of the various integrated projects in OpenStack. Every week we
have a
meeting that
tracks our progress toward this common goal. Why ?
Releases vs. Continuous deployment
The question is particularly valid if you take into account the type of
software that we produce. We don't really expect cloud infrastructure
providers to religiously download our source code tarballs every 6
months and run from that. For the largest installations, running much
closer to the master branch and continuously deploy the latest changes
is a really sound strategy. We invested a lot of effort in our gating
systems and QA automated testing to make sure the master branch is
always runnable. We'll discuss at the OpenStack
Summit next week how to
improve CD support in OpenStack. We backport bugfixes to the stable
branches post-release. So
why do we continue to single out a few commits and publish them as "the
release" ?
The need for cycles
The value is not really in releases. It is in release cycles.
Producing OpenStack involves the work of a large number of people. While
most of those people are paid to participate in OpenStack development,
as far as the OpenStack project goes, we don't manage them. We can't ask
them to work on a specific area, or to respect a given deadline, or to
spend that extra hour to finalize something. The main trick we use to
align everyone and make us all part of the same community is to have a
cycle. We have regular milestones that we ask contributors to target
their features to. We have a feature
freeze to encourage
people to switch their mindset to bugfixing. We have weekly meetings to
track progress, communicate where we are and motivate us to go that
extra mile. The common rhythm is what makes us all play in the same
team. The "release" itself is just the natural conclusion of that common
effort.
A reference point in time
Singling out a point in time has a number of other benefits. It's easier
to work on documentation if you group your features into a coherent set
(we actually considered shortening our cycles in the past, and the main
blocker was our capacity to produce good documentation often enough).
It's easier to communicate about OpenStack progress and new features if
you do it periodically rather than continuously. It's easier to have
Design Summits every 6 months
if you create a common brainstorm / implementation / integration cycle.
The releases also serve as reference points for API deprecation rules,
for stable release maintenance, for security backports.
If you're purely focused on the software consumption part, it's easy to
underestimate the value of release cycles. They actually are one of the
main reasons for the pace of development and success of OpenStack so
far.
The path forward
We need release cycles... do we need release deliverables ? Do we
actually need to bless and publish a set of source code tarballs ? My
personal view on that is: if there is no additional cost in producing
releases, why not continue to do them ? With the release tooling we have
today, blessing and publishing a few tarballs is as simple as pushing a
tag, running a script and sending an email. And I like how this formally
concludes the development cycle to start the stable maintenance period.
But what about Continuous Deployment ? Well, the fact that we produce
releases shouldn't at all affect our ability to continuously deploy
OpenStack. The master branch should always be in good shape, and we
definitely should have the necessary features in place to fully support
CD. We can have both. So we should have both.
{kind=link}