Yesterday we entered the Icehouse development
cycle
Feature Freeze. But with the incredible growth of the OpenStack
development community (508 different contributors over the last 30 days,
including 101 new ones !), I hear a lot of questions about it. I've
explained it on various forums in the past, but I figured it couldn't
hurt to write something a bit more definitive about it.
Why
Those are valid questions. Why freeze features ? That sounds very
anti-agile. Isn't our test-centric development model supposed to protect
us from regressions anyway ? Let's start with what feature freeze is
not. Feature freeze should only affect the integrated OpenStack release.
If you don't release (i.e. if you don't special-case certain moments in
the development), then feature freezing makes little sense. It's also
not a way to punish people who failed to meet a deadline. There are
multiple reasons that a given feature will miss a deadline, and most of
those are not the fault of the original author of the feature. We do
time-based releases, so some features and some developers will
necessarily be caught on the wrong side of the fence at some point and
need to wait for the next boat. It's an artifact of open innovation
projects.
Feature freeze (also known as "FF") is, obviously, about stopping adding
new features. You may think of it as artificially blocking your
progress, but this has a different effect on other people:
-
As was evidenced by the Icehouse cycle, good code reviewers are
a scarce resource. The first effect of feature freeze is that it
limits the quantity of code reviews and make them all about
bugfixes. This lets reviewers concentrate on getting as many
bugfixes in as possible before the "release". It also helps
developers spend time on bugfixes. As long as they can work on
features, their natural inclination (or their employer orders) might
conflict with the project interest at this time in the cycle, which
is to make that point in time we call the "release" as bug-free as
possible.
-
From a QA perspective, stopping the addition of features means
you can spend useful time testing "in real life" how OpenStack
behaves. There is only so much our automated testing will catch. And
it's highly frustrating to spend time testing software that
constantly changes under you.
-
QA is not the only group that needs to catch up. For the
documentation team, the I18N team, feature freeze is
essential. It's difficult to write documentation if you don't know
what will be in the end product. It's frustrating to translate
strings that are removed or changed the next day.
-
And then you have all the downstream consumers of the release that
can use time to prepare it. Packagers need software that doesn't
constantly change and add dependencies, so that they can prepare
packages for OpenStack projects that are released as close to our
release date as possible. The marketing team needs time to look
into what was produced over the cycle and arrange it in key messages
to communicate to the outside world at release time.
-
Finally, for release management, feature freeze is a tool to
reduce risk. The end goal is to avoid introducing an embarassing
regression just before release. By gradually limiting the impact of
what we accept in the release branch (using feature freeze, but also
using the RC
dance
that comes next), we try our best to prevent that.
Exceptions
For all these groups, it's critical that we stop adding features,
changing behavior, adding new configuration options, or changing
translatable strings as early as possible. Of course, it's a trade-off.
There might be things that are essential to the success of the release,
or things that are obviously risk-limited. That's why we have an
exception process: the Feature Freeze exceptions ("FFEs").
Feature freeze exceptions may be granted by the PTL (with the friendly
but strong advice from the release management team). The idea is to
weigh the raw benefit of having that feature in the release, against
the complexity of the code that is being brought in, its risk of causing
a regression, and how deep we are in feature freeze already. A
self-contained change that is ready to merge a few days after feature
freeze is a lot more likely to get an exception than a refactoring of a
key layer that still needs some significant work to land. It also
depends on how many exceptions were already granted on that project,
because at some point adding anything more just causes too much
disruption.
It's a difficult call to make, and the release management team is here
to help the PTLs make it. If your feature gets denied, don't take it
personally. As you saw there are a large number of factors involved. Our
common goal is to raise the quality of the end release, and every
feature freeze exception we grant is a step away from that. We just
can't take that many steps back and still guaranteeing we'll win the
race.
Open innovation vs. proprietary innovation
For companies, there are two ways to develop open source projects. The
first one is to keep design and innovation inside your corporate
borders, and only accept peripheral contributions. In that case you
produce open source software, but everything else resembles traditional
software development: you set the goals and roadmap for your product,
and organize your development activity to meet those goals, using Agile
or waterfall methodologies.
The second one is what we call open innovation: build a common and
level playing field for contributions from anywhere, under the auspices
of an independent body (foundation or other). In that case you don't
really have a roadmap: what ends up in the software is what the
contributors manage to push through a maintainers trust tree (think: the
Linux kernel) or a drastic code review / CI gate (think: OpenStack).
Products or services are generally built on top of those projects and
let the various participants differentiate on top of the common
platform.
Now, while I heavily prefer the second option (which I find much closer
to the ideals of free software), I recognize that both options are valid
and both are open source. The first one ends up attracting far less
contributions, but it works quite well for niche, specialized products
that require some specific know-how and where focused product design
gives you an edge. But the second works better to reach universal
adoption and total world domination.
A tragedy of the commons
The dilemma of open innovation is that it's a natural tragedy of the
commons. You need strategic contributions to keep the project afloat:
people working on project infrastructure, QA, security response,
documentation, bugfixing, release management which do not directly
contribute to your employer baseline as much as a tactical contribution
(like a driver to interface with your hardware) would. Some companies
contribute those necessary resources, while some others just get the
benefits of monetizing products or services on top of the platform
without contributing their fair share. The risk, of course, is that the
strategic contributor gets tired of paying for the free rider.
Open innovation is a living ecosystem, a society. Like all societies, it
has its parasites, its defectors, those which don't live by the rules.
And like all societies, it actually needs a certain amount of
defectors, as it makes the society stronger and more able to evolve. The
trick is to keep the amount of parasites down to a tolerable level. In
our world, this is usually done by increasing the difficulty or the cost
of defecting, while reducing the drawbacks or the cost of cooperating.
Keeping our society healthy
In his book Liars and Outliers, Bruce Schneier details the various
knobs a society can play with to adjust the number of defectors. There
are moral pressures, reputational pressures, institutional pressures and
security pressures. In open innovation projects, moral pressures and
security pressures don't work that well, so we usually use a combination
of institutional pressures (licensing, trademark rules) and reputational
pressures (praising contributors, shaming free riders) to keep defectors
to an acceptable level.
Those are challenges that are fully understood and regularly applied in
the Linux kernel project. For OpenStack, the meteoritic growth of the
project (and the expertise land-grab that came with it) protected us
from the effects of the open innovation dilemma so far. But the
Technical Committee shall keep an eye on this dilemma and be ready to
adjust the knobs if it starts becoming more of a problem. Because at
some point, it will.
StoryBoard is a project I started a few months ago. We have been running
into a number of issues with Launchpad (inability to have blueprints
spanning multiple code bases, inability to have flexible project group
views, inability to use non-Launchpad OpenID for login...), and were
investigating replacements. I was tired to explain why those
alternatives wouldn't work for our task tracking, so I started to
describe the features we needed, and ended up writing a proof-of-concept
to show a practical example.
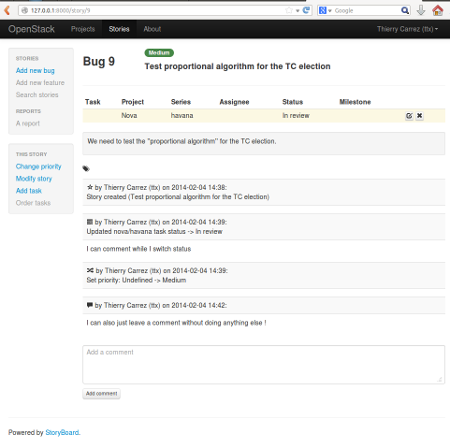
That proof-of-concept was sufficiently compelling that the
Infrastructure team decided we should follow the path of writing our own
tool. To be useful, task tracking for complex projects has to precisely
match your workflow. And the POC proved that it wasn't particularly
difficult to write. Then people from HP, Mirantis and RedHat joined this
effort.
My Django-based proof-of-concept had a definite last-century feel to it,
though. We wanted a complete REST API to cover automation and scripting
needs, and multiple clients on top of that. Time was ripe for doing
things properly and start building a team effort around this. Time was
ripe for... the StoryBoard sprint.
We gathered in Brussels for two days in advance of FOSDEM, in a meeting
room sponsored by the OpenStack Foundation (thanks!). On day 2 we were
12 people in the room, which was more than we expected !

Colette helped us craft a mission statement and structure our goals.
Michael presented an architecture (static JS client on top of
OpenStack-like REST service) that we blessed. Jaromir started to draw
wireframes. Sergey, Ruslan and Nikita fought uncooperative consulates
and traveled at night to be present on day 2. We also confirmed a number
of other technology choices (Bootstrap, AngularJS...). We discussed the
basic model, bikeshedded over StoryBoard vs. Storyboard and service
URLs. We got a lot covered, had very few breaks, ate nice food and drank
nice beer. But more importantly, we built a strong set of shared
understandings which should help us make progress as a united team going
forward.
We have automated testing and continuous deployment set up now, and once
the initial basic functionality is up (MVP0) we should iterate fast. The
Infrastructure program is expected to be the first to dogfood this, and
the goal is to have something interesting to present to other programs
by the Atlanta summit. To participate or learn more about StoryBoard,
please join us on #storyboard on Freenode IRC, or at our weekly
meeting.
Looking at our recently-concluded icehouse-2 development timeframe, we
landed far less features and bugfixes than we wanted and expected. That
created concerns about us losing our velocity, so I run a little
analysis to confirm or deny that feeling.
Velocity loss ?
If we compare icehouse to the havana cycle and focus on implemented
blueprints (not the best metric), it is pretty obvious that icehouse-2
was disappointing:
havana-1: 63
havana-2: 100
icehouse-1: 69
icehouse-2: 50
Using the first milestone as a baseline (growth of 10% expected), we
should have been at 110 blueprints, so we are at 45% of the expected
results. That said, looking at bugs gives a slightly different picture:
havana-1: 671
havana-2: 650
icehouse-1: 738
icehouse-2: 650
The first milestone baseline again gives a 10% expected growth, which
means the target was 715 bugs... but we "only" fixed 650 bugs (like in
havana-2). So on the bugfixes front, we are at 91% of the expected
result.
Comparing with grizzly
But havana is not really the cycle we should compare icehouse with.
We should compare with another cycle where the end-of-year holidays hit
during the -2 milestone development... so grizzly. Let's look at
the number of commits (ignoring merges), for a number of projects that
have been around since then. Here are the results for nova:
nova grizzly-1: 549 commits
nova grizzly-2: 465 commits
nova icehouse-1: 548 commits
nova icehouse-2: 282 commits
Again using the -1 milestone as a baseline for expected growth (here
+0%), nova in icehouse-2 ended up at 61% of the expected number of
commits. The results are similar for neutron:
neutron grizzly-1: 155 commits
neutron grizzly-2: 128 commits
neutron icehouse-1: 203 commits
neutron icehouse-2: 110 commits
Considering the -1 milestones gives an expected growth in commits
between grizzly and icehouse of +31%. Icehouse-2 is at 66% of
expected result. So not good but not catastrophic either. What about
cinder ?
cinder grizzly-1: 86 commits
cinder grizzly-2: 54 commits
cinder icehouse-1: 175 commits
cinder icehouse-2: 119 commits
Now that's interesting... Expected cinder growth between grizzly and
icehouse is +103%. Icehouse-2 scores at 108% of the expected,
grizzly-based result.
keystone grizzly-1: 95 commits
keystone grizzly-2: 42 commits
keystone icehouse-1: 116 commits
keystone icehouse-2: 106 commits
That's even more apparent with keystone, which had a quite disastrous
grizzly-2: expected growth is +22%, Icehouse-2 is at 207% of the
expected result. Same for Glance:
glance grizzly-1: 100 commits
glance grizzly-2: 38 commits
glance icehouse-1: 98 commits
glance icehouse-2: 89 commits
Here we expect 2% less commits, so based on grizzly-2 we should have
had 37 commits... icehouse-2 here is at 240% !
In summary, while it is quite obvious that we delivered far less than we
wanted to, due to the holidays and the recent gate issues, from a
velocity perspective icehouse-2 is far from being disastrous if you
compare it to the last development cycle where the holidays happened at
the same time in the cycle. Smaller projects in particular have handled
that period significantly better than last year.
We just need to integrate the fact that the October - April cycle
includes a holiday period that will reduce our velocity... and lower our
expectations as a result.
Every year, free and open source developers from all over Europe and
beyond converge in cold Brussels for a week-end of talks, hacking and
beer. OpenStack will be present !
We have a number of devroom and lightning talks already scheduled:
Saturday 12:20 in Chavanne (Virtualization and IaaS devroom)
Autoscaling best practices
Marc Cluet will look into autoscaling using Heat and Ceilometer as
examples.
Saturday 13:00 in Chavanne (Virtualization and IaaS devroom)
Network Function Virtualization and Network Service Insertion and
Chaining
Balaji Padnala will present NFV and how to deploy it using OpenStack
and OpenFlow Controller.
Saturday 13:40 in Chavanne (Virtualization and IaaS devroom)
oVirt and OpenStack Storage (present and future)
Federico Simoncelli will cover integration between oVirt and
Glance/Cinder for storage needs.
Saturday 15:00 in Chavanne (Virtualization and IaaS devroom)
Why, Where, What and How to contribute to OpenStack
I will go through a practical introduction to OpenStack development and
explain why you should contribute if you haven't already.
Saturday 16:20 in Chavanne (Virtualization and IaaS devroom)
Hypervisor Breakouts - Virtualization Vulnerabilities and OpenStack
Exploitation
Rob Clark will explore this class of interesting vulnerabilities from
an OpenStack perspective.
Saturday 17:40 in Chavanne (Virtualization and IaaS devroom)
oVirt applying Nova scheduler concepts for data center
virtualization
Gilad Chaplik will present how oVirt could reuse OpenStack Nova
scheduling concepts.
Sunday 10:00 in U.218A (Testing and automation devroom)
Preventing craziness: a deep dive into OpenStack testing
automation
Me again, in a technical exploration on the OpenStack gating system and
its unique challenges.
Sunday 13:40 in Chavanne (Virtualization and IaaS devroom)
Tunnels as a Connectivity and Segregation Solution for Virtualized
Networks
Join Assaf Muller for an architectural, developer oriented overview of
(GRE and VXLAN) tunnels in OpenStack Networking.
Sunday 16:20 in Chavanne (Virtualization and IaaS devroom)
Bring your virtualized networking stack to the next level
Mike Kolesnik will look into integration opportunities between oVirt
and OpenStack Neutron.
Sunday 17:00 in Ferrer (Lightning talks room)
Putting the PaaS in OpenStack
~~Dirk~~ Diane Mueller will give us an update on cross-community
collaboration between OpenStack, Solum, Docker and OpenShift.
Sunday 17:20 in Ferrer (Lightning talks room)
Your Complete Open Source Cloud
Dave Neary should explain how to mix OpenStack with oVirt, OpenShift
and Gluster to build a complete private cloud.
We'll also have a booth manned by OpenStack community volunteers ! I
hope to see you all there.