In the ancient times (circa 2012), as OpenStack started to grow significantly,
Ken Pepple created a
diagram
to represent the various OpenStack components and how information flowed
between them. This diagram took a life of its own, being included in one
version or another in every presentation to show in one spaghetti picture the
complexity of OpenStack.
As we kept adding new (more or less optional) components to the mix, we stopped
trying to represent everything in a single diagram, especially as the
Technical Committee refused to special-case some components over others. That
left us with a confusing list of 60+ project teams ranging from Nova to
Winstackers, and no way to represent clearly "OpenStack".
This situation was identified as a key issue by the Board of Directors, the
Technical Committee, the User Committee and the Foundation staff during a
stategic workshop held last year in Boston. As a result, a group formed to
define how to better communicate what OpenStack is, and a subgroup worked more
specifically on a new map to represent OpenStack. Here is the result:
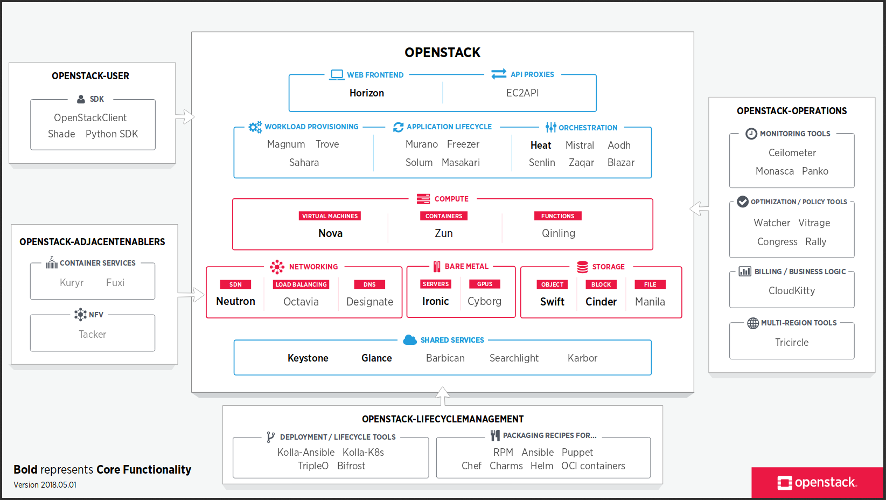
A number of things you should notice. First, the map is regularly updated.
This is the latest version, from May, 2018. The map is also versioned,
using a date-based number. So if someone copies it for their presentation
and it gets cargo-culted into generations of presentations from there on,
it should be pretty apparent that this may not be the latest available version.
Cartographers know that map design is more about what you leave out than
about what you represent. This map is very opinionated in that respect.
It is designed to be relevant to consumers of OpenStack technology.
So it only represents first-order deliverables, things that someone may opt
to install or use. That's the reason why it shows Nova, but not Oslo libraries:
it does not represent second-order deliverables that first-order deliverables
depend on. It also ignores plug-ins or drivers that run on a main deliverable
(like Storlets running onto Swift, Dragonflow running onto Neutron, or
magnum-ui running onto Horizon).
The remaining components are laid out in named "buckets", based on who the
consumer is and what question they answer. There is the main OpenStack
bucket, which contains components that provide a user-facing API, that you
may deploy to extend the capabilities of your cloud deployment. On the right,
the OpenStack-operations bucket contains add-on components that facilitate
operating an OpenStack cloud. On the bottom, the
OpenStack-lifecyclemanagement bucket shows the various solutions you can
use to facilitate installation and lifecycle management of an OpenStack
cloud. On the left, the OpenStack-user bucket contains tools that end users
of OpenStack clouds can install to help interact with a running OpenStack
cloud. And finally, the OpenStack-adjacentenablers bucket contains tools that
help other technology stacks (Kubernetes, NFV...) make use of OpenStack
services.
Inside each bucket, deliverables are approximately categorized based on what
service they deliver. In addition to that, the main OpenStack bucket is
organized in a semi-logical manner (base services at the bottom, higher-level
services at the top). An opinionated set of "core functionality" is marked in
bold to attract the attention of the casual observer to the most-consumed
components.
There are lots of different ways to slice this cake, and a lot of things do
not perfectly fit in the simplistic view that the map presents. The result is
obviously very opinionated, so it cannot please everyone. That's why it's
produced by the Foundation staff, with input from the Technical
Committee, the User Committee and the Board of Directors. That doesn't mean
its design cannot change, or be fixed over time to better represent the
reality.
Working on this exercise really helped me visualize "OpenStack" as a
product. You can see the main product (the OpenStack bucket), separate from
operational add-ons, deployment tools, client tools and technology bridges.
You can see things that do not fit well in the map, or stay at the edges of
the map, that we could consider cutting out if they are not successful.
We hope that this map helps people to visually represent OpenStack and can
replace the infamous spaghetti diagram in future slidedecks. The next step
is to communicate that map more widely, and leverage it more heavily on web
properties like the
Project Navigator.
You can always find the most recent version of the map at
www.openstack.org/openstack-map.
What are Meltdown and Spectre ?
Meltdown and Spectre are the brand names of a series of vulnerabilities
discovered by various security researchers around performance optimization
techniques built in modern CPUs. Those optimizations (involving superscalar
capabilities, out-of-order execution, and speculative branch prediction)
fundamentally create a
side-channel that can
be exploited to deduce the content of computer memory that should normally
not be accessible.
Why is it big news ?
It's big news because rather than affecting a specific operating system,
it affects most modern CPUs, in ways that cannot be completely fixed
(as you can't physically extract the flawed functionality out of your CPUs).
The real solution is in a new generation of CPU optimizations that will
not exhibit the same flaws while reaching the same levels of performance.
This is unlikely to come soon, which means we'll have to deal with workarounds
and mitigation patches for a long time.
Why is it business as usual ?
As Bruce Schneier
says, "you can't secure what you don't understand". As we build more complex
systems (in CPUs, in software, in policies), it is more difficult to build
them securely, and they can fail in more subtle ways. There will always be
new vulnerabilities and new classes of attacks found, and the answer is always
the same: designing defense in depth, keeping track of vulnerabilities found,
and swiftly applying patches. This episode might be big news, but the
remediation is still applying well-known techniques and processes.
Are those 2 or 3 different vulnerabilities ?
It is actually three different exploitation techniques of the same famility
of vulnerabilities, which need to be protected against separately.
-
CVE-2017-5753 (“bounds check bypass”, or variant 1) is one of the two
Spectre variants. It affects specific sequences within compiled applications,
which must be addressed on a per-binary basis. Applications that can be made
to execute untrusted code (e.g. operating system kernels or web browsers) will
need updates as more of those exploitable sequences are found.
-
CVE-2017-5715 (“branch target injection”, or variant 2) is the other
Spectre variant. It more generally works by poisoning the CPU branch
prediction cache to induce privileged applications to leak small bits of
information. This can be fixed by a CPU microcode update or by applying
advanced software mitigation techniques (like Google's Retpoline) to the
vulnerable binaries.
-
CVE-2017-5754 (“rogue data cache load”, or variant 3) is also called
Meltdown. This technique lets any unprivileged process read kernel memory
(and therefore access information and secrets in other processes running
on the same system). It is the easiest to exploit, and requires patching
the operating system to reinforce isolation of memory page tables at the
kernel level.
What is the impact of those vulnerabilities for OpenStack cloud users ?
Infrastructure as a service harnesses virtualization and containerization
technologies to present a set of physical, bare-metal resources as virtual
computing resources. It heavily relies on the host kernel security features
to properly isolate untrusted workloads, especially the various virtual
machines running on the same physical host. When those fail (like is the
case here), you can have a hypervisor break. An attacker in a hostile VM
running on an unpatched host kernel could use those techniques to access
data in other VMs running on the same host.
Additionally, if the guest operating system of your VMs is not patched
(or you run a vulnerable application) and run untrusted code on that VM
(or in that application), that code could leverage those vulnerabilities
to access information in memory in other processes on the same VM.
What should I do as an OpenStack cloud provider ?
Cloud providers should apply kernel patches (from their Linux distribution),
hypervisor software updates (from the distribution or their vendor) and CPU
microcode updates (from their hardware vendor) that workaround or mitigate
those vulnerabilities as soon as they are made available, in order to protect
their users.
What should I do as an OpenStack cloud user ?
Cloud users should watch for and apply operating system patches for their
guest VMs as soon as they are made available. This advice actually applies
to any computer (virtual or physical) you happen to use (including your phone).
Are patches available already ?
Some patches are out, some are still due. Kernel patches mitigating the
Meltdown attack are available upstream, but they are significant patches
with lots of side-effects, and some OS vendors are still testing them.
The coordinated disclosure process failed to keep the secret up to the
publication date, which explains why some OS vendors or distributions were
not ready when the news dropped.
It is also important to note that this is likely to trigger a long series
of patches, as the workarounds and mitigation patches are refined to reduce
side-effects and new bugs that those complex patches themselves create. The
best recommendation is to keep an eye on your OS vendor patches (and CPU
vendor microcode updates) for the coming months and apply all patches quickly.
Is there a performance hit in applying those patches ?
The workarounds and mitigation techniques are still being developed, so it
is a little early to say, and it will always depend on the exact workload.
However, since the basic flaw here lies in performance optimization techniques
in CPUs, most workarounds and mitigation patches should add extra checks,
steps and synchronization that will undo some of that performance
optimization, resulting in a performance hit.
Is there anything that should be patched on the OpenStack side ?
While OpenStack itself is not directly affected, it is likely that some of
the patches that are and will be developed to mitigate those issues will
require optimizations in software code to limit the performance penalty.
Keep an eye on our stable branches and/or your OpenStack vendor patches
to make sure you catch any of those.
Those vulnerabilities also shine some light on the power of side-channel
attacks, which shared systems are traditionally more vulnerable to. Security
research is likely to focus on such class of issues in the near future,
potentially discovering side-channel security attacks in OpenStack that
will need to be fixed.
Where can I learn more ?
You can find lots of explanations over the Internet. To understand the basic
flaw and the CPU technologies involved, I recommend reading
Eben Upton's great post.
If that's too deep or you need a good analogy to tell your less-technical
friends, I find
this one by Robert Merkel not too bad.
For technical details on the vulnerability themselves,
Jann Horn's post on Google Project Zero blog
should be first on your list. You can also read the
Spectre
and Meltdown papers.
For more information on the various mitigation techniques, I recommend
starting with
this article from Google's Security blog.
For information about Linux kernel patches in particular, I recommend
Greg Kroah-Hartman's post.
In less than two weeks, OpenStack upstream developers and project team members
will assemble in Denver, Colorado for a week of team discussions, kickstarting
the Queens development cycle.
Attending the PTG is a great way to make
upstream developers more efficient and productive: participating in the new
development cycle organization, solving early blockers and long-standing
issues in-person, and building personal relationships to ease interactions
afterwards.
What changed since Atlanta ?
The main piece of feedback we received from the Pike PTG in Atlanta was that
with the ad-hoc discussions and dynamic scheduling, it was hard to discover
what was being discussed in every room. This was especially an issue during
the first two days, where lots of vertical team members were around but did
not know which room to go to.
In order to address that issue while keeping the scheduling flexibility that
makes this event so productive, we created an IRC-driven dynamic notification
system. Each room moderator is able to signal what is being discussed right
now, and what will be discussed next in the #openstack-ptg IRC channel. That
input is then collected into a mobile-friendly webpage for easy access. That
page also shows sessions scheduled in the reservable extra rooms via Ethercalc,
so it's a one-stop view of what's being currently discussed in every room,
and what you could be interested in joining next.
The other piece of feedback that we received in Atlanta was that the
horizontal/vertical week slicing was suboptimal. Having all horizontal teams
(QA, Infra, Docs) meet on Monday-Tuesday and all vertical teams (Nova, Cinder,
Swift) meet on Wednesday-Friday was a bit arbitrary and did not make an optimal
use of the time available.
For Denver we still split the week in two, but with a slightly different
pattern. On Monday-Tuesday we'll have inter-team discussions, with rooms
centered more on topics than on teams, focused on solving problems.
On Wednesday-Friday we'll have intra-team discussions, focused on organizing,
prioritizing and bootstrapping the work for the rest of the deployment cycle.
Such a week split won't magically suppress all conflicts obviously, but we
hope it will improve the overall attendee experience.
What rooms/topics will we have on Monday-Tuesday ?
Compute stack / VM & BM WG (#compute):
In this room, we’ll have discussions to solve inter-project issues within the base compute stack (Keystone, Cinder, Neutron, Nova, Glance, Ironic…).
API SIG (#api):
In this room, we’ll discuss API guidelines to further improve the coherence and compatibility of the APIs we present to the cloud user. Members of the SIG will also be hosting guided reviews of potential API changes, see the openstack-dev mailing list for more details.
Infra / QA / RelMgt / Stable / Requirements helproom (#infra):
Join this room if you have any questions about or need help with anything related to the development infrastructure, in a large sense. Can be questions around project infrastructure configuration, test jobs (including taking advantage of the new Zuul v3 features), the “Split Tempest plugins” Queens goal, release management, stable branches, global requirements.
Packaging WG (#packaging):
In this room, we’ll discuss convergence and commonality across the various ways to deploy OpenStack: Kolla, TripleO, OpenStackAnsible, Puppet-OpenStack, OpenStack Chef, Charms...
Technical Committee / Stewardship WG (#tc):
In this room, we’ll discuss project governance issues in general, and stewardship challenges in particular.
Skip-level upgrading (#upgrading):
Support for skip-level upgrading across all OpenStack components will be discussed In this room. We’ll also discuss increasing the number of projects that support rolling upgrades, zero-downtime upgrades and zero-impact upgrades.
GUI helproom / Horizon (#horizon):
Join this room if you have questions or need help writing a Horizon dashboard for your project, and want to learn about the latest Horizon features. Horizon team members will also discuss Queens cycle improvements here.
Oslo common libraries (#oslo):
Current and potential future Oslo libraries will be discussed in this room. Come to discuss pain points or missing features, or to learn about libraries you should probably be using.
Docs / I18n helproom (#docs-i18n):
Documentation has gone through a major transition at the end of Pike, with more doc maintenance work in the hands of each project team. The Docs and I18n teams will meet in this room and be available to mentor and give guidance to Doc owners in every team.
Simplification (#simplification):
Complexity is often cited as the #1 issue in OpenStack. It is however possible to reduce overall complexity, by removing unused features, or deleting useless configuration options. If you’re generally interested in making OpenStack simpler, join this room!
Make components reusable for adjacent techs (#reusability):
We see more and more OpenStack components being reused in open infrastructure stacks built around adjacent technology. In this room we’ll tackle how to improve this component reusability, as well as look into things in adjacent communities we could take advantage of.
CLI / SDK helproom / OpenStackClient (#cli):
In this helproom we’ll look at streamlining our client-side face. Expect discussions around OpenStackClient, Shade and other SDKs.
"Policy in code" goal helproom (#policy-in-code):
For the Queens cycle we selected “Policy in code” as a cross-project release goal. Some teams will need help and guidance to complete that goal: this room is available to help you explain and make progress on it.
Interoperability / Interop WG / Refstack (#interop):
Interoperability between clouds is a key distinguishing feature of OpenStack clouds. The Interop WG will lead discussions around that critical aspect in this room.
User Committee / Product WG (#uc):
The User Committee and its associated subteams and workgroups will be present at the PTG too, with a goal all week to close the feedback loop from operators back to developers. This work will be prepared in this room on the first two days of the event.
Security (#security):
Security is a process which requires continuous attention. Security-minded folks will gather into this room to further advance key security functionality across all OpenStack components.
Which teams are going to meet on Wednesday-Friday ?
The following project teams will meet for all three days:
Nova, Neutron, Cinder, TripleO, Ironic, Kolla,
Swift, Keystone, OpenStack-Ansible, Infrastructure, QA,
Octavia, and Glance.
The following project teams plan to only meet for two days, Wednesday-Thursday:
Heat, Watcher, OpenStack Charms, Trove, Congress,
Barbican, Mistral, Freezer, Sahara, Glare, and
Puppet OpenStack.
Join us!
We already have more than 360 people signed up, but we still have room for you!
Join us if you can. The ticket price will increase this Friday though,
so if you plan to register I'd advise you to do so ASAP to avoid the
last-minute price hike.
The event hotel is pretty full at this point (with the last rooms available
priced accordingly), but there are
lots of other options
nearby.
See you there!
Back in March in Boston, the OpenStack Board of Directors, Technical Committee,
User Committee and Foundation staff members met for a strategic workshop. The
goal of the workshop was to come up with a list of key issues needing attention
from OpenStack leadership. One of the strategic areas that emerged from that
workshop is the need to improve the feedback loop between users and developers
of the software. Melvin Hillsman volunteered to lead that area.
Why SIGs ?
OpenStack was quite successful in raising an organized, vocal, and engaged
user community. However the developer and user communities are still mostly
acting as separate communities. Improving the feedback loop starts with
putting everyone caring about the same problem space in the same rooms and
work groups. The Forum (removing the artificial line between the Design Summit
and the Ops Summit) was a first step in that direction. SIGs are another step
in addressing that problem.
Currently in OpenStack we have various forms of workgroups, all attached to
a specific OpenStack governance body: User Committee workgroups (like the
Scientific WG or the Large Deployment WG), upstream workgroups (like the API
WG or the Deployment WG), or Board workgroups. Some of those are very focused
on a specific segment of the community, so it makes sense to attach them to a
specific governance body. But most are just a group of humans interested in
tackling a specific problem space together, and establishing those groups in
a specific community corner sends the wrong message and discourages
participation from everyone in the community.
As a result (and despite our efforts to communicate that everyone is welcome),
most TC-governed workgroups lack operator participants, and most UC-governed
workgroups lack developer participants. It's clearly not because the scope
of the group is one-sided (developers are interested in scaling issues,
operators are interested in deployment issues). It's because developers
assume that a user committee workgroup about "large deployments" is meant
to gather operator feedback rather than implementing solutions. It's because
operators assume that an upstream-born workgroup about "deployment" is only
to explore development commonalities between the various deployment strategies.
Or they just fly below the other group's usual radar. SIGs are about breaking
the artificial barriers and making it clear(er) that workgroups are for
everyone, by disconnecting them from the governance domains and the useless
upstream/downstream division.
SIGs in practice
SIGs are neither operator-focused nor developer-focused. They are open groups,
with documented guidance on how to get involved. They have a scope, a clear
description of the problem space they are working to address, or of the use
case they want to better support in OpenStack. Their membership includes
affected users that can discuss the pain points and the needs, as well as
development resources that can pool their efforts to achieve the groups goals.
Ideally everyone in the group straddles the artificial line between operators
and developers and identifies as a little of both.
In practice, SIGs are not really different from the various forms of workgroups
we already have. You can continue to use the same meetings, git repositories,
and group outputs that you used to have. To avoid systematic cross-posting
between the openstack-dev and the openstack-operators mailing-lists, SIG
discussions can use the new openstack-sigs mailing-list,
SIG members can take advantage of our various events (PTG,
Ops meetups, Summits) to meet in person.
Next steps
We are only getting started. So far we only have one SIG: the "Meta" SIG, to
discuss advancement of the SIG concept. Several existing workgroups have
expressed their willingness to become early adopters of the new concept, so
we'll have more soon. If your workgroup is interested in being branded as a
SIG, let Melvin or myself know, we'll guide you through the process (which at
this point only involves being listed on a
wiki page). Over time we
expect SIGs to become the default: most community-specific workgroups would
become cross-community SIGs, and the remaining workgroups would become more
like subteams of their associated governance body.
And if you have early comments or ideas on SIGs, please join the Meta
discussion on the
openstack-sigs mailing-list,
(using the [meta] subject prefix)!
It is now pretty well accepted that open source is a superior way of
producing software. Almost everyone is doing open source those days.
In particular, the ability for users to look under the hood and make
changes results in tools that are better adapted to their workflows.
It reduces the cost and risk of finding yourself locked-in with a vendor
in an unbalanced relationship. It contributes to a virtuous circle of
continuous improvement, blurring the lines between consumers and producers.
It enables everyone to remix and invent new things. It adds up to the
common human knowledge.
And yet
And yet, a lot of open source software is developed on (and with the help
of) proprietary services running closed-source code. Countless open source
projects are developed on GitHub, or with the help of Jira for bugtracking,
Slack for communications, Google docs for document authoring and sharing,
Trello for status boards. That sounds a bit paradoxical and hypocritical --
a bit too much "do what I say, not what I do". Why is that ? If we agree
that open source has so many tangible benefits, why are we so willing to
forfeit them with the very tooling we use to produce it ?
But it's free !
The argument usually goes like this: those platforms may be proprietary, they
offer great features, and they are provided free of charge to my open source
project. Why on Earth would I go through the hassle of setting up,
maintaining, and paying for infrastructure to run less featureful solutions ?
Or why would I pay for someone to host it for me ? The trick is, as the
saying goes, when the product is free, you are the product. In this case,
your open source community is the product. In the worst case scenario, the
personal data and activity patterns of your community members will be sold
to 3rd parties. In the best case scenario, your open source community is
recruited by force in an army that furthers the network effect and makes it
even more difficult for the next open source project to not use that
proprietary service. In all cases, you, as a project, decide to not bear the
direct cost, but ask each and every one of your contributors to pay for it
indirectly instead. You force all of your contributors to accept the
ever-changing terms of use of the proprietary service in order to participate
to your "open" community.
Recognizing the trade-off
It is important to recognize the situation for what it is. A trade-off.
On one side, shiny features, convenience. On the other, a lock-in of your
community through specific features, data formats, proprietary protocols or
just plain old network effect and habit. Each situation is different. In
some cases the gap between the proprietary service and the open platform
will be so large that it makes sense to bear the cost. Google Docs is pretty
good at what it does, and I find myself using it when collaborating on
something more complex than etherpads or ethercalcs. At the opposite end of
the spectrum, there is really no reason to use Doodle when you can use
Framadate. In the same vein, Wekan
is close enough to Trello that you should really consider it as well.
For Slack vs. Mattermost vs. IRC, the
trade-off is more subtle. As a sidenote, the cost of lock-in is a lot
reduced when the proprietary service is built on standard protocols. For
example, GMail is not that much of a problem because it is easy enough to
use IMAP to integrate it (and possibly move away from it in the future).
If Slack was just a stellar opinionated client using IRC protocols and
servers, it would also not be that much of a problem.
Part of the solution
Any simple answer to this trade-off would be dogmatic. You are not unpure
if you use proprietary services, and you are not wearing blinders if you
use open source software for your project infrastructure. Each community
will answer that trade-off differently, based on their roots and history.
The important part is to acknowledge that nothing is free. When the choice
is made, we all need to be mindful of what we gain, and what we lose.
To conclude, I think we can all agree that all other things being equal, when
there is an open-source solution which has all the features of the
proprietary offering, we all prefer to use that. The corollary is, we all
benefit when those open-source solutions get better. So to be part of the
solution, consider helping those open source projects build something as
good as the proprietary alternative, especially when they are pretty close
to it feature-wise. That will make solving that trade-off a lot easier.
{kind=link}